
What Is RAG and Why Does It Matter for Text-to-SQL?
Trying to use LLMs to generate SQL without providing your schema and business rules is almost a waste of time.
It generally hallucinates, making up table or column names that don’t exist. The LLM doesn’t know your business logic, your naming conventions, or your schema constraints. You can try stuffing your schema into every prompt, but that quickly becomes inefficient, brittle, and doesn’t scale.
So what’s the alternative?
What Is RAG?
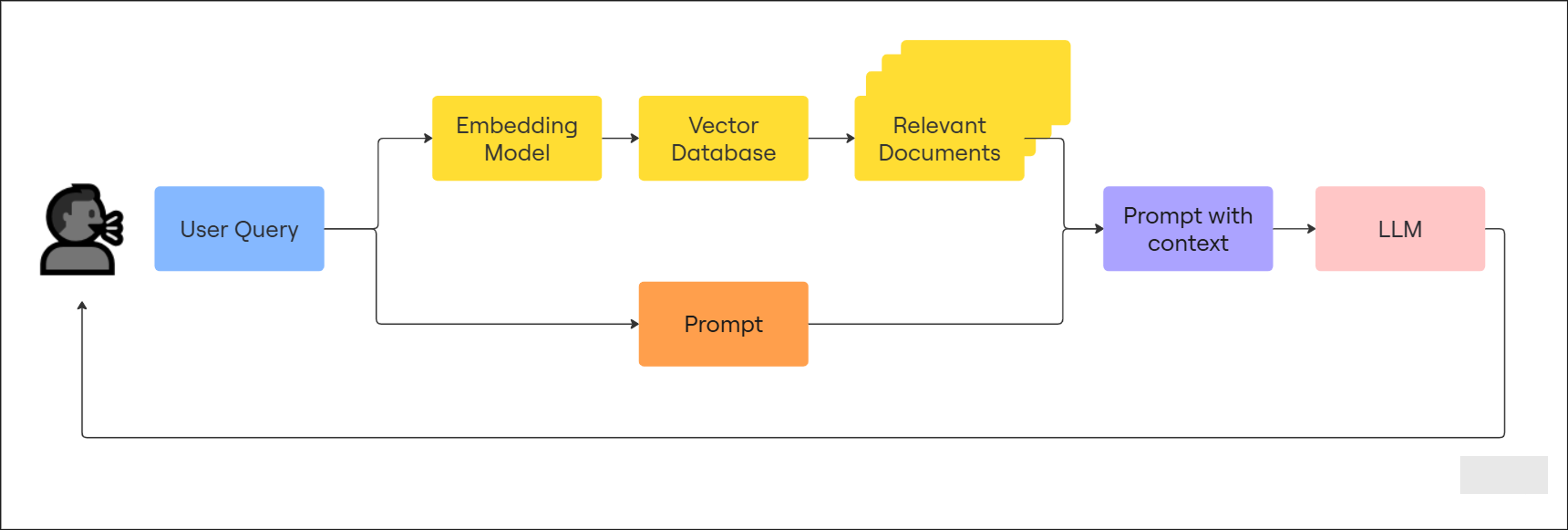
Retrieval-Augmented Generation (RAG) is an AI architecture that combines traditional retrieval methods (like search engines or vector databases) with language models. Instead of relying solely on an LLM’s memory, RAG feeds it contextual data from your own knowledge base (like schemas, documentation, or logs) before generating a response.
“RAG (Retrieval-Augmented Generation) is an AI framework that combines the strengths of traditional information retrieval systems (such as search and databases) with the capabilities of generative large language models (LLMs). By combining your data and world knowledge with LLM language skills, grounded generation is more accurate, up-to-date, and relevant to your specific needs.”
Think of It Like a Librarian
Imagine asking a librarian a question. Instead of guessing or making up answers, they know exactly which books to reference, where to find them, and how to extract what’s useful for you. That’s what RAG does, it retrieves relevant, authoritative context for the LLM to use when answering.
Why RAG Matters for Text-to-SQL
I’ve seen the difference firsthand.
When I asked WrenAI a question, it didn’t just “guess” a SQL query, it retrieved my schema and used that in the prompt. The result? Queries that actually ran.
Benefits of using RAG for Text-to-SQL:
- Reduces hallucinations by grounding output in real schema
- Adapts to different schemas without hardcoding or retraining
- More accurate and relevant queries tailored to your business context
- Customization-ready with no fine-tuning
- Fresh information from changing databases or schema evolution
How to Build a RAG System for SQL Generation Using LangChain and a Local Vector Database
Let’s walk through how to build a simple but functional RAG pipeline for Text-to-SQL, using LangChain’s new v0.2+ interface.
🛠️ Environment Setup: Python Virtualenv + Dependencies
Before diving into code, let’s make sure your environment is clean and ready. I’m using Python 3.12 for this exercise.
Step 1: Create a Virtual Environment
python -m venv venv
# On Windows:
venv\Scripts\activate
Step 2: Install Required Libraries
pip install langchain langchain-openai langchain-community faiss-cpu
✅ langchain-openai provides OpenAI embeddings + models
✅ langchain-community includes community-maintained vector stores like FAISS
✅ faiss-cpu is for local semantic search
Step 3: Setup and Imports
You’ll notice we’re using both langchain_openai and langchain_community, which reflects the recent modular split in LangChain v0.2+.
from langchain_openai import OpenAIEmbeddings, OpenAI
from langchain_community.vectorstores import FAISS
from langchain.text_splitter import CharacterTextSplitter
from langchain.prompts import PromptTemplate
from langchain_core.runnables import RunnablePassthrough
import os
# Set your OpenAI API key
os.environ["OPENAI_API_KEY"] = "sk-..." # Use env vars or secret manager in production
✅ Why this matters: We’re pulling in everything needed to load text data, chunk it, embed it, store it in a retriever, build a prompt, and finally generate SQL using OpenAI.
Step 4: Define Your Data Schema (Context)
This is your domain knowledge. We simulate a simple database schema in plain text.
schema_docs = """
Table: orders
Columns: order_id, customer_id, order_date, total_amount
Table: customers
Columns: customer_id, name, email, region
"""
✅ Why this matters: RAG systems work best when the context is rich and specific. Here, we define the structure the AI will use to answer questions.
Step 5: Chunk the Text
We split the schema into chunks. Even if the schema is small now, chunking is a good habit to support scalability.
splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=0)
docs = splitter.create_documents([schema_docs])
✅ Why this matters: Large documents can confuse LLMs. Chunking ensures each piece stays within token limits and remains semantically focused.
Step 6: Embed and Store with FAISS
We convert text chunks into vector embeddings using OpenAI and index them using FAISS, a fast, in-memory vector store.
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(docs, embeddings)
retriever = vectorstore.as_retriever()
✅ Why this matters: This is the “retrieval” in RAG. When a user asks a question, we use this retriever to find the most relevant schema chunks.
Step 7: Define the Prompt Template
This is the instruction format you give the LLM. It tells the model: “Here’s the schema. Now answer this question by generating SQL.”
prompt = PromptTemplate(
input_variables=["context", "question"],
template="""
You are an AI assistant that writes SQL queries based on a database schema.
Schema:
{context}
Question:
{question}
SQL Query:
"""
)
✅ Why this matters: Prompt engineering is core to RAG. We combine context + question into a structured input the LLM can reason over.
Step 8: Create the LCEL Chain (LangChain Expression Language)
Here we wire together the components into a pipeline: Retriever ➝ Prompt ➝ LLM
llm = OpenAI(temperature=0)
retrieval_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
)
✅ Why this matters: LCEL makes your pipeline modular, inspectable, and easier to test. RunnablePassthrough() just forwards the raw question as-is.
Step 9: Ask a Question and Run the Chain
Now you can send a natural language question to the pipeline and get back an AI-generated SQL query:
question = "What’s the total sales by region?"
response = retrieval_chain.invoke(question)
print(response)
Expected Output:
SELECT customers.region, SUM(orders.total_amount) AS total_sales
FROM orders
INNER JOIN customers ON orders.customer_id = customers.customer_id
GROUP BY customers.region;
Full code:
from langchain_openai import OpenAIEmbeddings, OpenAI
from langchain_community.vectorstores import FAISS
from langchain.text_splitter import CharacterTextSplitter
from langchain.prompts import PromptTemplate
from langchain_core.runnables import RunnablePassthrough
import os
# Set your API key
os.environ["OPENAI_API_KEY"] = "YOUR-OPENAI-API-KEY"
# Example schema as plain text
schema_docs = """
Table: orders
Columns: order_id, customer_id, order_date, total_amount
Table: customers
Columns: customer_id, name, email, region
"""
# Step 1: Split schema into chunks
splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=0)
docs = splitter.create_documents([schema_docs])
# Step 2: Embed and create FAISS vector store
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(docs, embeddings)
retriever = vectorstore.as_retriever()
# Step 3: Prompt template
prompt = PromptTemplate(
input_variables=["context", "question"],
template="""
You are an AI assistant that writes SQL queries based on a database schema.
Schema:
{context}
Question:
{question}
SQL Query:
"""
)
# Step 4: Define components for LCEL chain
llm = OpenAI(temperature=0)
# Create retriever -> prompt -> llm pipeline
retrieval_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
)
# Step 5: Invoke the LCEL chain
question = "What’s the total sales by region?"
response = retrieval_chain.invoke(question)
# Output result
print(response)
✅ Why this matters: This is the end-to-end RAG pipeline, no manual SQL needed, just your schema and a natural language question.
Summary: Why This Is RAG
This system retrieves relevant schema text (R), augments the prompt with it (A), and uses a generative model to answer your question (G). That’s Retrieval-Augmented Generation.
Final Thoughts
This RAG-powered approach is very simple, but still close to how real-world analysts or engineers operate, they consult the schema, then write SQL. LLMs can now do the same.
By bringing together semantic retrieval and generative reasoning, RAG systems give us the best of both worlds: precision and language flexibility. And as tools like LangChain mature, building these pipelines is becoming not just possible, but practical.
Cheers,
Jorge Rocha